

Discussion on core platform for Big Data
Author / Huang Zhezhun [Issue Date: 2014/9/5]
Introduction on Big Data
Big Data means huge amounts of data or massive amounts of data. This is just the literal meaning, but looking deeper, we see that Big Data is making big waves in the global information and technology world. According to Gartner's definition, "Huge amounts of data are a type of information having volume, variety and velocity and a new data processing method to help decision making and improving the production process is needed. Volume means that the data quantity needing analysis is large and data size cannot be accurately acquired, processed, or analyzed through artificial work and then converted to useful information. Variety means data includes structured data and unstructured data. Velocity means that the data is not static but is produced daily at any time, so the speed of data analysis should keep up with the speed of data production. These three data characteristics constitute Big Data as it is discussed in today's global information and technology world.
Big Data is regarded as a new wave of science and technology after cloud computing. According to Wikibon's Big Data market survey, the Big Data market opportunities increase year by year, and its key investment prospects are: Computing, Storage, development of analysis applications (App & Analytics) and Professional Services. It is predicted that overall output can reach $50 billion in 2017, as shown in figure 1. However, customers in different industries have different demands for Big Data, as shown in figure 2. The banking and securities industry focuses on volume and velocity, so it also goes with the industrial and natural resources industries. The multimedia and communications industry focuses on volume and variety as do government units. Technology companies put forward all kinds of products, to meet customers' varied demands for Big Data. The core of the current mainstream product is Hadoop pushed by Yahoo, Google and Facebook, and each technology manufacturer is launching all kinds of Big Data applications based on Hadoop.
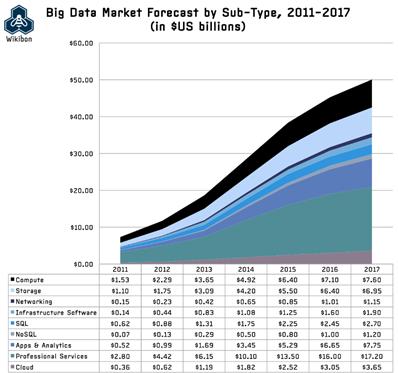
Figure 1: Big Data market forecast
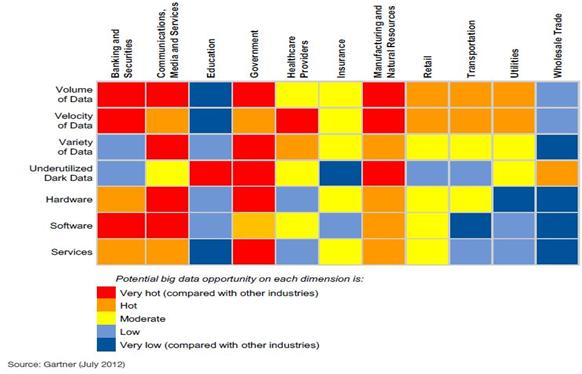
Figure 2: Big Data demands of each industry
Introduction on Hadoop
With the spread of the Internet, more and more people publish news through the network, and the data volume of the Internet causes index growth, but the search engine company Google is not troubled by such a huge amount of data, on the contrary, it processes data of more than 1 petabyte daily, and creates a web page index for users to search those web pages content quickly. In fact, very few companies in the world can process such a large amount of data, especially highly unstructured data like web content. There has been speculation about how Google does it, until when in 2003 and 2004 Google published two papers, "The Google File System" and "Graphs: Simplified Data Processing on Large Clusters." Both papers discussed Google's Big Data processing strategy which is realized through a "storage system with distributed computing ability." This set off a wave of Big Data. Many technology companies and the open source community dashed to imitate the system, which resulted in Hadoop, a comprehensive solution most closely resembling the Big Data strategy used by Google.
Before Hadoop, there are three ways for enterprises to deal with Big Data: relational databases, Data Warehouses, and Grid Computing. Relational databases are a good random access storage device and almost all application systems combine with relational databases, but they are rarely used to store data at the petabytes level. Further, they are not suitable for storage of unstructured data. Data warehouses are an outspread of relational databases, and can store data at the petabytes level, but must live on mainframes, meaning typical enterprises cannot afford the start-up cost. Grid Computing uses multiple servers with a synchronization operation to achieve mainframe-like computing power. It has horizontal expansion and initial costs are much lower than Data Warehouses. Many people compare Grid Computation with Hadoop. The biggest difference between them is that because for Grid Computing arithmetic device and storage device are separated, it needs to rely on a SAN (Storage Area Network) to store and exchange data. When encountering huge amounts of data, network bandwidth becomes a bottleneck for Grid Computing.
From some cases we find that Hadoop really can solve the problems that enterprises could not handle in the past. The New York Times decided to convert the contents of all their past newspapers from 1851 to 1980 to PDF files so that customers could browse the newspaper content through the web. To make a fast counter-attack against the emerging Internet media, the New York Times chose Hadoop to complete this task and to their excitement, everything worked and was completed in just one day. Morgan Bank (J. P. Morgan) already had thirty thousand sets of database dealing with daily transaction data before implementing Hadoop, however, they still had no way to deal with unstructured data, so they used Hadoop to build their business fraud detection system. In the past Facebook did Big Data analysis through Oracle Data warehousing, however, with the growth of data, horizontal expansion became a very important and now more than 80% of the analysis of Facebook is accomplished through Hadoop. Facebook has become part of the Hadoop ecosystem.
Introduction to Hadoop Solution Provider
The Hadoop ecosystem has remained quite active. The Hive project initiated by Facebook offers familiar SQL operation interfaces allowing users to execute SQL for accessing Hadoop data. The Pig project launched by Yahoo offers similar shell scripts letting users use Hadoop without writing programs. The Sqoop project provides an ETL tool to import database data into Hadoop. The Flume project supports a variety of network protocols to allows many kinds of sources to be imported into Hadoop. The Oozie project helps integrating work by providing workflow definition tools . Even if the Hadoop ecosystem is fairly active, for many enterprises it is still a daunting consideration and they do not dare to embrace this new Big Data technology. The biggest barrier to entry is version compatibility. The development community is fragmented, and we cannot determine all the suites in a given Hadoop cluster are stable versions, so Hadoop professional services companies have been appearing. They have unified testing for suites developed by different Hadoop developers, and then repackage them into version control storage (Repository) for enterprise users.
The well-known professional Hadoop labels are Cloudera, Hortonworks and MapR. In early 2014, Intel spent $7.1 billion acquiring 18% of Cloudera; in 2014 HP spent $50 million to strengthen its cooperation with Hortonworks; MapR obtained $110 million in capital injections from Google and Qualcomm in 2014. Now a three-way confrontation has formed. Cloudera is the earliest established professional Hadoop services company with many well-known Hadoop consultant experts, such as Tom White, Eric Sammer, and Lars George. Cloudera has more than 400 customers worldwide and has the largest market share.
Cloudera's Hadoop version control storage is called CDH (Cloudera 's Distribution, Apache Hadoop), as shown in figure 3. Users connect to the Cloudera CDH and directly install Hadoop through usingyum. They no longer need to download the compilation of the original file under various Apache Hadoop Projects, greatly reducing the difficulty of installation and configuration. In addition, for enterprise users, Cloudera provides Cloudera Enterprise, which strengthens Hadoop's security mechanism, and installs Hadoop's related suites on dozens of hosts through a single hub allowing enterprise users to quickly set up a Hadoop cluster. In addition to providing suite management and cluster management software, Cloudera also provides education, training, and professional certification services to help enterprises get their personnel up to speed on Hadoop. Currently the certifications offered from Cloudera are the Hadoop Admin CCAH, Hadoop Developer CCDH, CCP: Data Scientist and the HBase Specialist CCSHB.
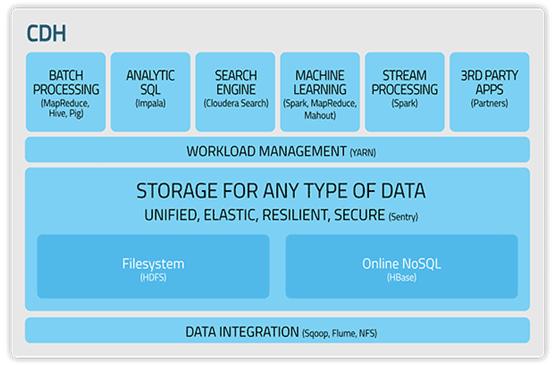
Figure 3: Cloudera's Distribution, including Apache Hadoop
Cloudera is highly professional, so it can provide the latest, the best and the most mature Hadoop technology for enterprise users. In 2014, CDH 5 placed Spark into the default installation projects. Spark, a distributed computing framework developed by the University of Berkeley, is similar to traditional MapReduce, but it uses memory to store intermediate data, known as Resilient Distributed Dataset (RDD). This greatly improves the processing speed, by nearly 100 times, of of the original MapReduce. Although Spark requires more memory, it is different from Impala and Stinger and does not need hundreds of Gigabytes of memory to expand space. This allows enterprise customers to significantly improve computational speed given a reasonable hardware investment. For developers, the biggest attraction of Spark is that they can write programs more intuitively and don't need to work as Mapper and Reducer respectively, therefore, development time is significantly reduced. Because of Spark's strengths, Mahout, the well-known Hadoop machine learning project, in 2014 stopped submitting codes related to MapReduce and the Hive project, which only supported MapReduce conversion in the past, began supporting Spark. By Cloudera's suggestion, we can expect Spark's popularity will increase and may eclipse MapReduce.
Next generation enterprise Big Data analysis platform
With Cloudera as the core, it's quite reasonable to build an entire Big Data enterprise solution, but the Cloudera is insufficient. Hadoop even given a small amount of data has disappointing response time and performance. Even using Cloudera Impala only brings us to nearly real-time performance so there is still a milliseconds gap between Hadoop's response time and that of traditional relational databases. In fact, Hadoop is designed to answer the big question, rather than the frequently asked small question. The typical big problem is, for example, how much is the average daily turnover over 20 years? For businesses it's this Big problem that makes it difficult to build a data center with the ability to handle Big Data. Return on investment for Big Data projects must reach a certain level. Therefore, basing on the concept of a Cloudera Enterprise Hub, the SYSCOM Group put forward the architecture of the next generation Enterprise Big Data analysis platform, shown in figure 4.
When building next generation enterprise Big Data analysis platforms, the SYSCOM Group considers the following elements: horizontal expansion, the ability to deal with Big Data, the ability to receive and release Open Data, Data Mining, rich visual rendering, and quick query response. Cloudera Hadoop is scalable, and meets the needs of Big Data simultaneously from three dimensions; HP Vertica is fast, and has horizontal expansion flexibility and the ability to data mine; Tableau, QlikView, and others, have wonderful visual effects; Informatica, Syncsort, MS SSIS, and others, are the mainstream of the ETL market. For statisticians, Cloudera Hadoop's built-in Mahout may not be enough, so we integrate R language into Cloudera Hadoop, expecting to get useful information from Big Data. Released to the engineers the information and even make them become the Open Data to reuse the data.
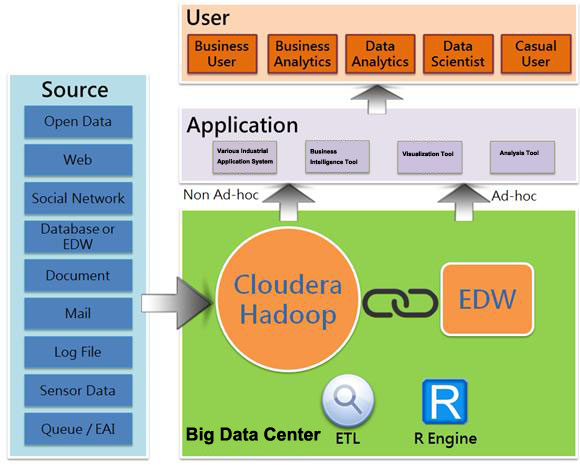
Figure 4: Next generation enterprise Big Data analysis platform
Bibliographies
‧http://www.gartner.com/newsroom/id/1731916
‧http://wikibon.org/wiki/v/Big_Data_Vendor_Revenue_and_Market_Forecast_2013-2017
‧https://www.gartner.com/doc/2077415/market-trends-big-data-opportunities
‧http://dl.acm.org/citation.cfm?id=945450
‧http://research.google.com/archive/mapreduce.html
‧http://open.blogs.nytimes.com/2007/11/01/self-service-prorated-super-computing-fun/?_php=true&_type=blogs&_r=0
‧http://www.reuters.com/article/2014/03/31/us-intel-cloudera-idUSBREA2U0ME20140331
‧http://www.zdnet.com/hp-invests-50-million-in-hortonworks-forges-big-data-partnership-7000031965/
‧http://www.mapr.com/company/press-releases/mapr-closes-110-million-financing-led-google-capital
‧http://spark.apache.org/
‧https://mahout.apache.org/
‧http://blog.cloudera.com/blog/2014/07/apache-hive-on-apache-spark-motivations-and-design-principles/
Innovator's Solution, Clayton M. Christensen, Journals of the world