

Shallow talk on Mass Information
Author/Chen Mingda [Issue Date: 2014/6/23]
Preface
In the past two years the subject of Big Data has been raised more often. Both in the academic world and the business world, Big Data seems to have become the next battleground. Under going a scouring by the technology industry, will it retain its shine after? Or, will it become just another illusion in the technology dustbin? This article discusses the definition of Big Data and its possible future applications. Living in these rapidly changing times, both the applications of and the possible future development of Big Data are worthy of our close attention, because perhaps the seeds from which the next wave of scientific and technological revolution spring are buried in the Big Data sea, waiting for us to discover.
What is Big Data?
As its name suggests, Big Data is a large amount of data, which for us is a very abstract concept. How much data on earth can be called Big Data? Because data volume is increasing, what kind of inspiration can Big Data offer us? On the network, there are hundreds of thousands of definitions of Big Data, and in my opinion a reasonable definition is, "Big data is data with vast volume, variety and veracity and can be collected, analyzed, processed, saved," and this definition quite clearly points out the basic characteristics of Big Data. First, the definition of "Big" is slightly out of perspective, to more accurate, so-called Big Data means a complete data set. In addition to the completeness of the data set, more data, of course, may result in more unexpected interpretation results after the analysis. Among a large amount of data, variety and veracity must be ensured, because fabricated data will cause a certain degree of distortion within the results; second, content with variety can ensure objectivity of the results; lastly and based on past experience, the amount of data and its processing time have an almost linear relationship, that is, when there is more information to deal with and analyze, the time spent will increase linearly and relative to the amount of data. But with the current scientific and technological progress, hardware support, multithreading, parallel computing techniques, and so on, we are able to efficiently quickly handle these vast amounts of data.
Big Data Revolution
After our introduction to Big Data, you must have some doubt in your heart: even now we are able to collect a lot of data, “so what?” Most doubt comes from the analysis of data, using all sample data, instead of a sample survey to improve accuracy. If your consideration of Big Data ends here then you've missed something. , for example, Google found very long ago, according to search keywords in a geographic area, it's possible to predict whether disease is looming, and the degree of precision is staggering and the speed - time of discovery is almost more synchronized than is possible with the local health department. What does this represent? Google doesn't need to collect specimens from door-to-door — just by using the publics Internet search keywords, a certain pattern, can predict whether influenza or disease outbreaks are taking place in a specific location, which of course is closely related to people's use of the Internet to find answers, and it is this kind of behavior that contributes to today's phenomenon that Big Data statistics and analysis and the results often can uncover unexpected results.
These innovations brought by Big Data in fact take place around us, such as e-mail spam filtering, dating sites pairing, search condition suggestions, automatic advertising automatic tracking while we surf the Internet — overall a and better language translation software. These are the products of the information revolution, and have already been implemented. Moreover in the near future, more innovations will appear, such as self-driving vehicles, artificial machine intelligence, and machine learning. The effects brought about by Big Data are absolutely beyond our imagination. It can be predicted that this will be a comprehensive reform that'll overthrow old fashioned thinking, old fashioned life styles, and even our way of living.
NoSQL
Along with the rise of Big Data, one of the resulting changes has been the database revolution, but relational databases concepts do not apply to Big Data applications, so NoSQL is becoming one of the important and core concepts in the discussion of Big Data. What is NoSQL? Referring to the definition in NoSQL Distilled, simply speaking, a database using NoSQL represents opening source codes. Most NoSQL databases have been developed in the early 21st century and are a collection of databases that do not using SQL, are not perfectly defined, and have no outline type. NoSQL provides data models that better fit the requirements of applications, simplifies the correspondence between programs and databases, and in this way raise the productivity of applications development. NoSQL predominately shows advantages when executing on clusters, so if there is Big Data, it's more suitable to use NoSQL's more traditional relational database. For software developers, part of the process of developing a program is finding a productive programming model that is suitable for their application and ensures the required data access and flexibility.
Designing on the traditional relational model and aggregation thinking
Traditional relational databases record all of the elements and the corresponding relations between them, but they cannot distinguish aggregation relationships thus cannot use an aggregation structure to store and distribute data. However, NoSQL belongs to the family of databases that use aggregation structures to store data, and have the further advantage in that they execution in a cluster environment. In this way, information is maintained together and can by clearly defined in aggregation. Ultimately we can put this data on the same node to make data storage management easy. Refer to NoSQL Distilled and having examined some examples we are able to more clearly understand the difference between the two. The following is a simple example using an order system:
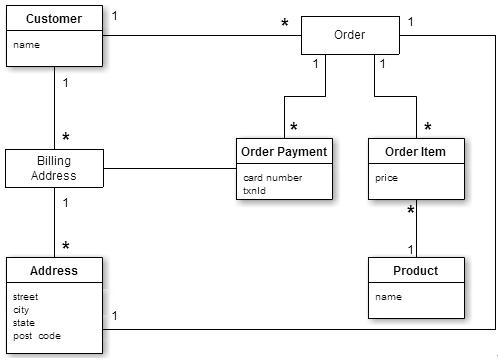
figure 1: data model of a relational database
From figure 1, we see that this is a relational database model storing information on users, catalogues, orders, shipping addresses, billing addresses, payment data, etc.
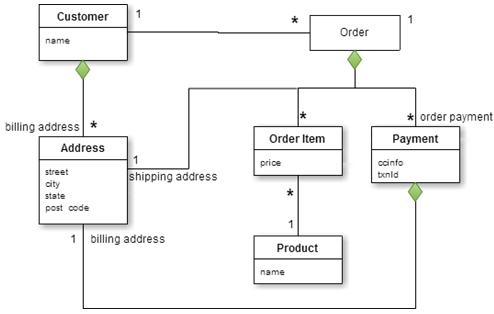
figure 2: gathered data model
From figure 2, we see that there are two main aggregations: Customer and Order. Customer contains the billing addresses list. Order contains the list of Order items, shipping address and payment data. Payment data itself contains the billing address for the payment. Order and Customer only have an aggregation relationship, and do not exist in the same aggregation, which is intended to minimize the number of accessed aggregations and interaction of data. After learning about the relational database model and the aggregate data model, we should have a certain understanding about the difference between them. The result of the data model design is not absolute, and particularly there is no standard answer for the gathered boundary definition, so we must consider how to access data and the corresponding model at the beginning of the design.
The Dark Side Behind Big Data
There are two sides Big Data to consider and these can lead us in different directions. One point we should think about is that maybe the collected data are completely pointless, under this hypothesis, the results of our Big Data efforts could be a very seriously incorrect. For example, new outlets are reporting that a disease outbreak will occur in a certain country. People who have seen this news will surf the net to find related information and if we analyze according to this information, misjudgment may result. In addition, the source data collection also needs special attention. When there are sampling errors or insufficient objective sampling in the data, devastating results may result. We cannot be too careful. Given this scenario, although Big Data did not prove a causality correlation , but if we fully abandon causality, any Big Data analysis will be pointless. How does one achieve a balance between the two? This will be an important issue in the future.
For most people, one core values of Big Data is relevance. As the basis of forecasts and predictions, possibilities abound — the area where disease will strike, whether a person will be sick according to a health exam, when machinery and equipment will breakdown. Further, when applied to the prison system, Big Data may be able to predict the probability that a paroled prisoner will commit a crime . From this perspective, prediction affects our future generations who will lose autonomous decision-making and responsibility. For all people, conscience choice, free will, and even ethics and morals also will be replaced by algorithmic predictions. This will lead to another terrible phenomenon: relying too much on machines. In this way people will lose judgment, and free choice free, considerations worth pondering.
Conclusions
In the past, both computing power and storage capacity used to analyze Big Data were too expensive, but now as science and technology have developed ever faster, our thinking also should keep pace. Life can be recorded and quantified, and thinking of using data must also change. A large amount of data has caused qualitative change. We must not be complacent to confine ourselves to those data that can be collected and studied. As long as we are able to grasp a general outline, we can seize a development trend, find and model any correlation between the trend and the data, and benefit from the results previously hidden within the data.
Bibliographies
‧http://www.dotblogs.com.tw/jimmyyu/archive/2013/03/07/big-data-analysis.aspx
‧"15 classes to understand NoSQL" (NoSQL Distilled written by Pramod J. Sadalage,Martin Fowler), translated by Wu Yaozhuan, GoTop press, 2013.
‧"Big Data" written by Viktor Mayer-Schonberger and Kenneth Cukier, translated by Lin Junhong, Jonesky Press, 2013.