

Shallow talk on NoSQL database -Redis
Author/Huang Junxiao [Issue Date: 2015/8/24]
Preface
With the development of the Internet, we have changed from one server to multiple servers. When starting to establish data backups, we need to add a buffer layer to adjust the queries and add more hardware. Finally, we need to split the data across multiple clusters, and reconstruct a large number of application logic to adapt to this resulting segmentation. Soon after, you'll find yourself already limited by the data structures that were designed just a few months ago.
With the rise of web 2.0, there are challenges that relational databases by themselves cannot overcome and their deficiencies are more and more obvious. The main points are as follows:
1.Demand for highly concurrent read and write data.
2.Demand for high-efficiency store and access to vast amounts of data.
3.Demand for high scalability and availability.
4.Demand for database transactional consistency.
5.Demand for database realism and efficiency of reads and writes.
6.Demand for complex SQL queries, especially for the associated query.
NoSQL is an abbreviation of Not only SQL. NoSQL does not use SQL as the query language. Its data storage does not require a fixed table model, and it often avoids the use of the SQL join operation, in addition, it generally has a horizontal scalability characteristic.
NoSQL is divided into four categories:
1.Key-Value, Redis for example.
2.Document-Oriented, MongoDB for example.
3.Wide Column Store, Cassandra for example.
4.Graph-Oriented, Neo4J for example.
The primary technology introduced in this writing is Redis (Key-Value).
Redis Introduction
Redis (Remote Dictionary Server) is an open source (BSD licensed), advanced key value cache and store system. Redis's keys include strings, hashes, lists, sets, sorted sets, bitmap and overweight logarithm (hyperloglog), so Redis is usually called a data structure server. You can run an atomic operation on these types, such as adding a string, increasing the number of hash values, adding an element to the list, calculating the intersection, the union and the difference set of the collection, or retrieve the element with the highest ranking from an ordered set.
In order to meet high performance requirements, Redis uses an in-memory dataset. According to your usage scenario, you can occasionally dump a data set to disk, or append every command to the log to achieve persistence. However, if you just need a feature-rich, networked memory cache, persistence can be disabled.
Redis also supports asynchronous master-slave replication, very fast non-blocking initial synchronization, automatic reconnecting and local resynchronization when the network has been unavailable. Other features are:
- Transaction
- subscribe/publish
- Lua script
- Key With TTL
- LRU recovery key
- Automatic failover
Supports multiple languages:
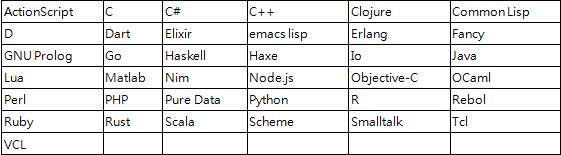
Redis's advantages:
Mainly in the following aspects:
- performance: Redis supports over 100K per second read and write frequency.
- Rich data types: Redis Ssupports strings, lists, hashes, sets of binary cases and data type operations of ordered sets.
- Rich features: Redis supports publish/subscribe, notice, key expiration, and more.
- Redis supports atomic operations on complex data structures , which is a different evolutionary path from other databases. Redis's data types are based on the basic data structures and are transparent to the programmer, so there is no need for additional abstraction.
- Redis runs in-memory but can be persisted to disk, so you need to balance the memory when do high-speed read and write operations for different data sets, and generally the amount of data should not be greater than the hardware memory. Another advantage of in-memory databases is that operations on the same complex data structure is very simple in memory compared with disk, in this way, Redis can execute many instructions with high internal complexity. In addition, at disk formats, additional compression is used because there is no requirement for random access.
Redis's operating environment
Redis is written in the ANSI C language, and without additional dependence, runs on most POSIX systems, such as Linux, * BSD, and OS X. Redis is developed and well-tested on Linux and OS X, and Linux is the recommend deployment environment.
Redis also runs on derived systems from Solaris and SmartOS for example, but support needs to be strengthened.
There is no official support for Windows builds, but Microsoft has developed and maintains a 64-bit version of Windows. Also, you can use Microsoft Azure to create a Redis server.
Redis operating instructions
After a Redis server is successfully created, you can operate it with Redis's officially offered redis-cli. The following is a simple explanation for operating instructions basing on data structures supported by Redis.
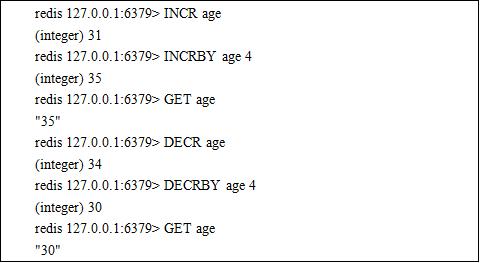
1. String Type
Redis can store binary safe strings with a maximum length of 1GB.

In fact String type can also be used to store digitals and supports addition and subtraction operations for digitals.
2. List Type
Redis can store data in a list and do many kinds of operations on the list.
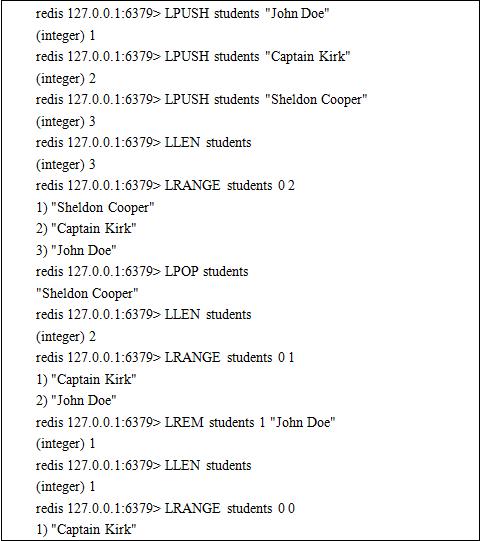
Redis also supports many modification operations.

3. Sets Type
Redis can store a series of distinct values as a collection.

Sets structure also supports the corresponding modification operations.

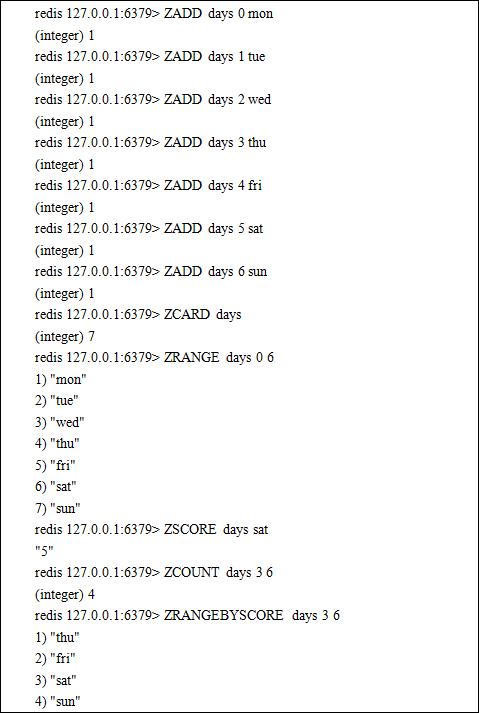
4. Sorted Sets Type
Sorted sets are similar to sets. The difference is that data in a sorted set there is a score attribute and when written into the set is sorted by it.
5. Hash Type
Redis can store keys for data with multiple attributes (e.g., user1.uname user1.passwd).
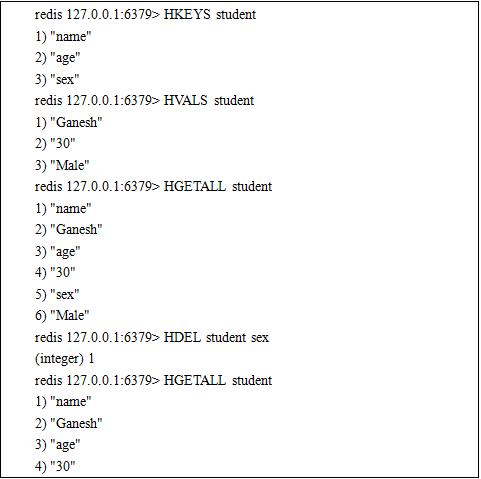
Hash data supports bulk Modification and acquisition.

6. Redis supports a feature that allows you to push data into an information pipe and then other people can get this data by subscribing to the pipe.
1. Subscribe to an information pipe: use a client to subscribe to the pipe

Another client is pushing information into this pipe.

And then the first client can get the information.

2. Subscribe to pipes in a certain batch mode: use the following command to subscribe to all information pipes at the beginning of channels.

Push information into two pipes on another client.

And then the first client can get the pushed information.

7. Data Expiration Settings
Redis supports setting the expiration time according to the key, and the expiration value will be deleted (from the view of the client). The TTL command is used to get the expiration time of a key value (-1 indicates no expiration).

In the following command, the EXISTS command is used first to check whether the key value exists and then an expiration time of 5 seconds is set.

Examine the result in 5 seconds.

The expiration time of 5 seconds has past.
In the above section, the expiration time is directly set to a time period, however, you can set the expiration time as a time point. Next, we illustrate how to set the expiration time to 2011-09-24 00:40:00.

8. Transaction
Redis itself supports some simple combinational commands, for example, all commands ending with NX are used to run a command when this value does not exist.
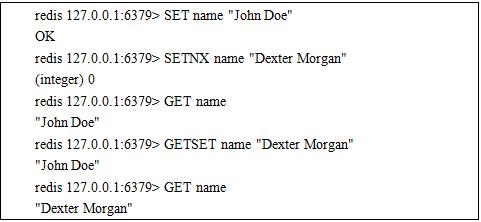
Of course, Redis also supports user-defined command combinations. Users can combine several commands to be execute by MULTI and EXEC.
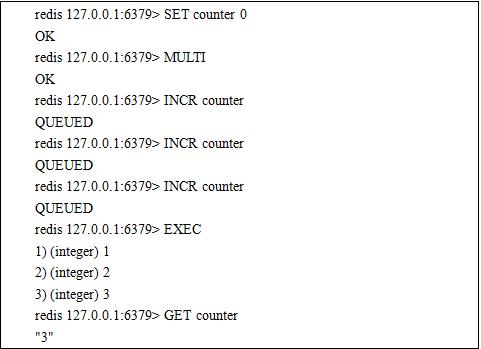
You also can use the DICARD command to interrupt the execution of a command sequence.

Epilogue
The big data has become an unstoppable trend in this era that is marked by fast development of our networks, quick exchange of information and a competitive environment. Therefore, it is bound to be helpful for employees in the information industry to understand and learn about NoSQL databases. Redis is one of the most popular NoSQL databases and is worth our attention.
References
Redis official website
Try Redis
Redis introduction in Chinese
Systematic presentation of Redis
Memory Database Practice - Redis introduction to explain profound theories in simple language
Interpret four major families of NoSQL databases